

Blackwell Ultra GB300 to najwydajniejszy układ obliczeniowy NVIDIA przeznaczony do sztucznej inteligencji. Producent zapowiada ogromny skok wydajności i pamięci, który umożliwi obsługę jeszcze większych modeli AI.
Najwydajniejszy chip dla AI
NVIDIA po raz kolejny podnosi poprzeczkę w segmencie układów obliczeniowych dla sztucznej inteligencji. Blackwell Ultra GB300 to rozszerzenie obecnej generacji Blackwell, które już trafiło do kluczowych klientów. Mimo że na premierę architektury Rubin musimy jeszcze poczekać, firma wprowadza istotne zmiany w swojej aktualnej linii produktów.

Gigantyczna liczba tranzystorów i nowa architektura
Blackwell Ultra GB300 powstał w procesie TSMC 4NP (5 nm). Chip składa się aż z 208 miliardów tranzystorów. To około 2,5 razy więcej niż w poprzedniej generacji Hopper. Warto podkreślić, że GB300 to w rzeczywistości dwa połączone ze sobą układy scalone, komunikujące się przez interfejs NV-HBI o przepustowości 10 TB/s.
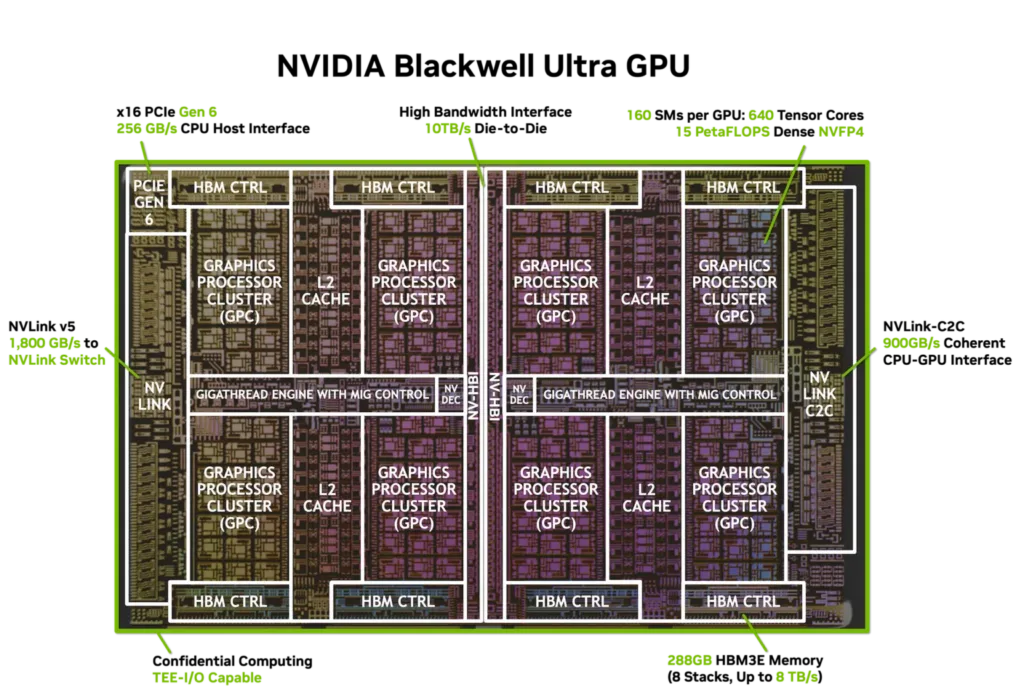
Każdy układ obejmuje 160 rdzeni SM, a w nich 128 rdzeni CUDA oraz cztery rdzenie Tensor piątej generacji. W sumie daje to 20 480 rdzeni CUDA, 640 rdzeni Tensor i 40 MB pamięci Tensor (TMEM). Dzięki temu układ świetnie sprawdzi się w zadaniach wymagających ogromnej mocy obliczeniowej, szczególnie w trenowaniu i wnioskowaniu dużych modeli AI.
Więcej pamięci dla modeli AI
Jednym z najważniejszych ulepszeń w Blackwell Ultra GB300 jest pamięć. Układ dysponuje aż 288 GB pamięci HBM3e na GPU. To aż 3,6 razy więcej niż Hopper H100 i o 50 procent więcej niż wcześniejsze układy Blackwell.
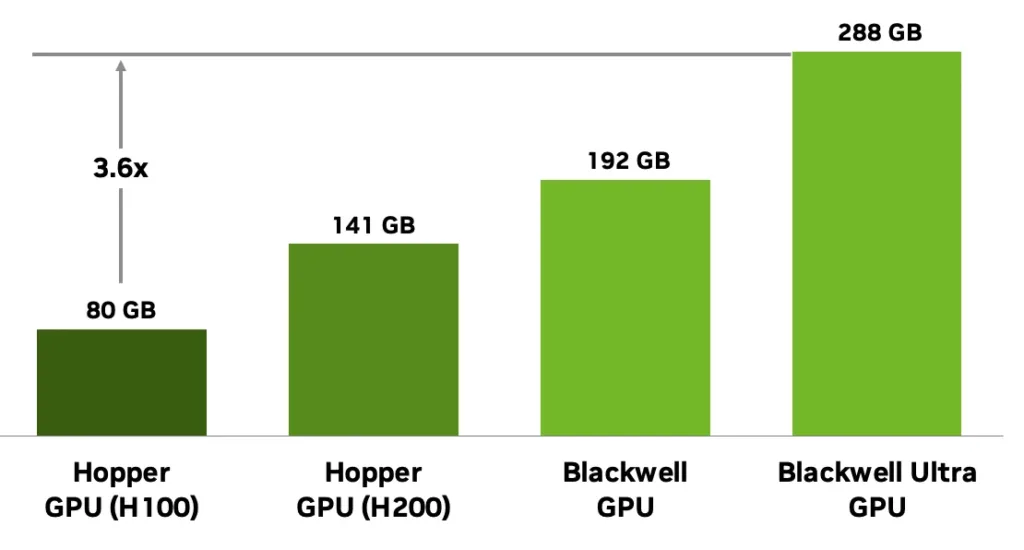
Większa pojemność pamięci oznacza możliwość obsługi modeli o bilionach parametrów bez konieczności ciągłego korzystania z pamięci podręcznej. Co więcej, daje to możliwość wykonywania wnioskowania przy większej liczbie jednoczesnych zadań oraz rozszerzania kontekstu w dużych systemach językowych.
Nowa generacja rdzeni Tensor i Transformer Engine
Blackwell Ultra GB300 korzysta z rdzeni Tensor piątej generacji i drugiej wersji silnika Transformer Engine. Dzięki temu układ osiąga wyższą przepustowość i niższe opóźnienia w różnorodnych zadaniach AI, zarówno w gęstych, jak i w rzadkich obliczeniach.
Przyspieszone zostały także operacje wymagające dużej uwagi (attention) w modelach typu Transformer. Podwojenie przepustowości jednostek SFU pozwala nawet dwukrotnie zwiększyć szybkość obliczeń warstw attention w porównaniu z poprzednią generacją. W rezultacie chip lepiej radzi sobie z długimi sekwencjami danych i przetwarzaniem tekstów naturalnych języków.
Specjalne silniki do danych multimodalnych
Blackwell Ultra GB300 został wyposażony w dodatkowe jednostki sprzętowe. NVDEC i NVJPEG odpowiadają za dekodowanie wideo i obrazów bez obciążania rdzeni CUDA. Dzięki temu możliwe jest szybkie przetwarzanie treści multimedialnych w czasie rzeczywistym.
Ponadto układ posiada silnik dekompresji danych o przepustowości 800 GB/s. Rozwiązanie to zmniejsza obciążenie procesora głównego i przyspiesza ładowanie skompresowanych zbiorów danych. NVIDIA integruje te funkcje z biblioteką DALI, co znacznie ułatwia przygotowanie danych do trenowania sieci neuronowych.
Wydajność i efektywność energetyczna
Według NVIDII, Blackwell Ultra GB300 to nie tylko większa moc, ale też większa efektywność. Producent podkreśla, że układ zapewnia o 50 proc. więcej mocy obliczeniowej NVFP4 i o połowę więcej pamięci HBM. Dzięki temu możliwe jest trenowanie i wnioskowanie w większej skali przy zachowaniu wysokiej efektywności energetycznej.
Przyspieszone operacje softmax zwiększają liczbę tokenów przetwarzanych na sekundę, zarówno w skali jednego użytkownika, jak i całego centrum danych. W rezultacie Blackwell Ultra pozwala obniżyć koszty działania serwerowni i zwiększyć ich wydajność.
Grace Blackwell Ultra Superchip i NVL72
NVIDIA zaprezentowała również rozwiązanie systemowe oparte na nowym chipie. Grace Blackwell Ultra Superchip łączy procesor Grace z dwoma układami Blackwell Ultra GB300. Taki zestaw oferuje do 30 PFLOPS mocy w gęstych operacjach i 40 PFLOPS dla zadań rzadkich.
Do tego dochodzi 1 TB zunifikowanej pamięci oraz przepustowość sieci 800 GB/s dzięki technologii ConnectX-8 SuperNIC. Superchip stanowi podstawę systemu GB300 NVL72, chłodzonego cieczą racka z 36 superchipami, połączonymi za pomocą przełączników NVLink 5. Całość osiąga imponujące 1,1 EXAFLOPS obliczeń FP4.
Dzięki temu system zapewnia aż 50 razy wyższą wydajność niż platformy Hopper, 10 razy niższe opóźnienia i 5 razy większą przepustowość na megawat. To ogromny skok dla fabryk AI i centrów danych.
Co dalej?
Choć przyszłość należy do architektury Rubin, NVIDIA konsekwentnie rozwija rodzinę Blackwell. Blackwell Ultra GB300 jest wyraźnym dowodem, że firma nie zamierza zwalniać tempa. Tymczasem rynek AI wciąż rośnie, a zapotrzebowanie na coraz wydajniejsze układy tylko się zwiększa.
Dzięki takim rozwiązaniom jak GB300 czy system NVL72, NVIDIA chce utrzymać pozycję lidera w wyścigu o dominację w sztucznej inteligencji.